
Sobre la base de un modelo anterior llamado UniGen, un equipo de investigadores de Apple demostró UniGen 1.5, un sistema que puede manejar la comprensión, generación y edición de imágenes dentro de un solo modelo. Aquí están los detalles.
Una actualización del UniGen original
En mayo pasado, un equipo de investigadores de Apple publicó un estudio llamado UniGen: Enhanced Training & Test-Time Strategies for Unified Multimodal Understanding and Generation.
En este trabajo, introdujeron un modelo de lenguaje grande multimodal unificado capaz de comprender y generar imágenes dentro de un solo sistema, en lugar de depender de modelos separados para cada tarea.
Apple ha publicado ahora una continuación de esta investigación en un artículo titulado UniGen-1.5: Improving Image Generation and Editing by Unifying Rewards in Reinforcement Learning.
UniGen-1.5
Esta nueva investigación amplía UniGen al agregar capacidades de edición de imágenes al modelo, aún dentro de un marco unificado, en lugar de separar la comprensión, generación y edición en diferentes sistemas.
Reunir estas capacidades en un solo sistema es un desafío, ya que comprender y generar imágenes requiere diferentes enfoques. Sin embargo, los investigadores dicen que un modelo unificado puede utilizar su capacidad de comprensión para mejorar el rendimiento de la generación.
Según ellos, uno de los principales desafíos en la edición de imágenes es que los modelos a menudo tienen dificultades para comprender completamente instrucciones de edición complejas, especialmente cuando los cambios son sutiles o muy específicos.
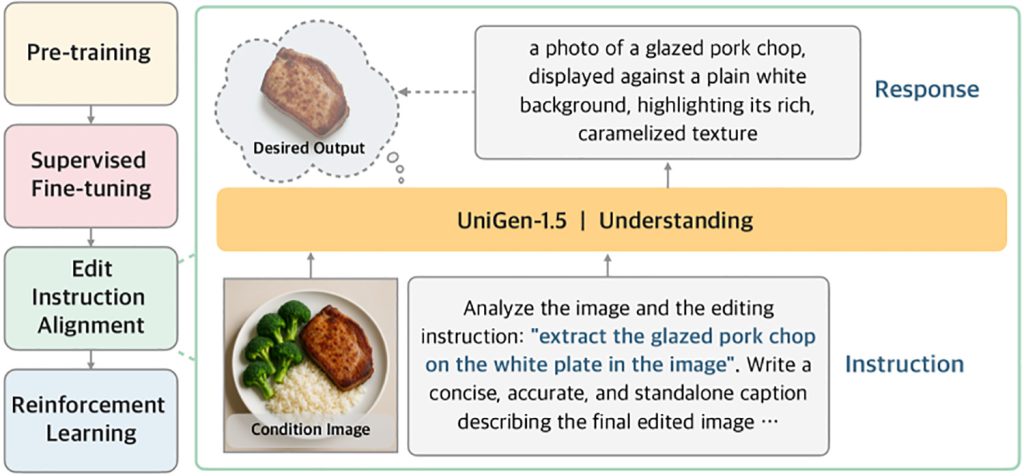
Para solucionar esto, UniGen-1.5 introduce un nuevo paso posterior al entrenamiento llamado Editar alineación de instrucciones:
“Además, observamos que el modelo sigue siendo inadecuado para manejar varios escenarios de edición después de un ajuste fino controlado debido a una comprensión insuficiente de las instrucciones de edición. Por lo tanto, proponemos la alineación de las instrucciones de edición como una etapa liviana después de SFT para mejorar la alineación entre las instrucciones de edición y la semántica de la imagen de destino. Específicamente, toma la condición y la imagen de instrucción como entradas y está optimizada para predecir el contenido semántico de la imagen de destino a través de descripciones textuales. Los resultados experimentales sugieren que esta etapa es muy útil para aumentar la eficiencia de la edición.
En otras palabras, antes de pedirle al modelo que mejore sus resultados mediante el aprendizaje por refuerzo (que entrena al modelo recompensando los mejores resultados y castigando los peores), los investigadores primero lo entrenan para inferir una descripción textual detallada de lo que debe contener la imagen editada, basándose en la imagen original y las instrucciones de edición.
Este paso intermedio ayuda al modelo a internalizar mejor la edición prevista antes de generar la imagen final.
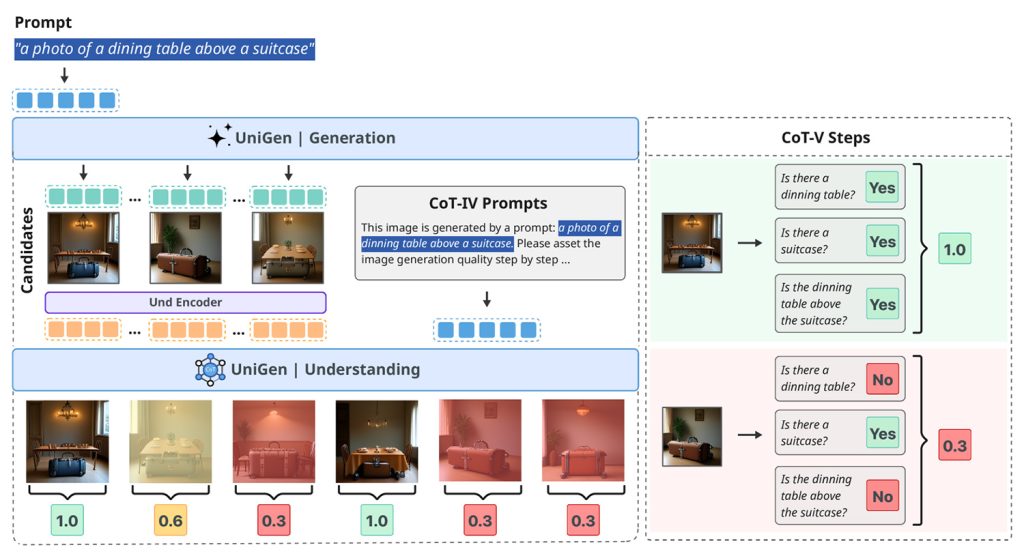
Luego, los investigadores utilizan el aprendizaje por refuerzo de una manera que quizás sea la contribución más importante del artículo: utilizan el mismo sistema de recompensa tanto para la generación como para la edición de imágenes, lo que anteriormente ha sido un desafío porque las ediciones pueden variar desde ajustes menores hasta transformaciones completas.
Como resultado, cuando se prueba en varios puntos de referencia estándar de la industria que miden qué tan bien los modelos siguen instrucciones, mantienen la calidad visual y manejan ediciones complejas, UniGen-1.5 iguala o supera a muchos modelos de lenguaje grande multimodales, propietarios y abiertos de última generación:
A través de los esfuerzos anteriores, UniGen-1.5 proporciona una base más sólida para avanzar en la investigación MLLM unificada y establece un rendimiento competitivo en métricas de comprensión, generación y edición de imágenes. Los resultados experimentales muestran que UniGen-1.5 obtiene puntuaciones de 0,89 y 86,83 en GenEval y DPG-Bench, superando significativamente a métodos recientes como BAGEL y BLIP3o. Para la edición de imágenes, UniGen-1.5 logra puntuaciones generales de 4,31 en ImgEdit, superando a los modelos recientes de código abierto como OminiGen2 y comparable a modelos propietarios como GPT-Image-1.
Aquí hay algunos ejemplos de capacidades de generación de texto a imagen y edición de imágenes de UniGen-1.5 (desafortunadamente, los investigadores parecen haber cortado por error las indicaciones para el segmento de texto a imagen en la primera imagen):

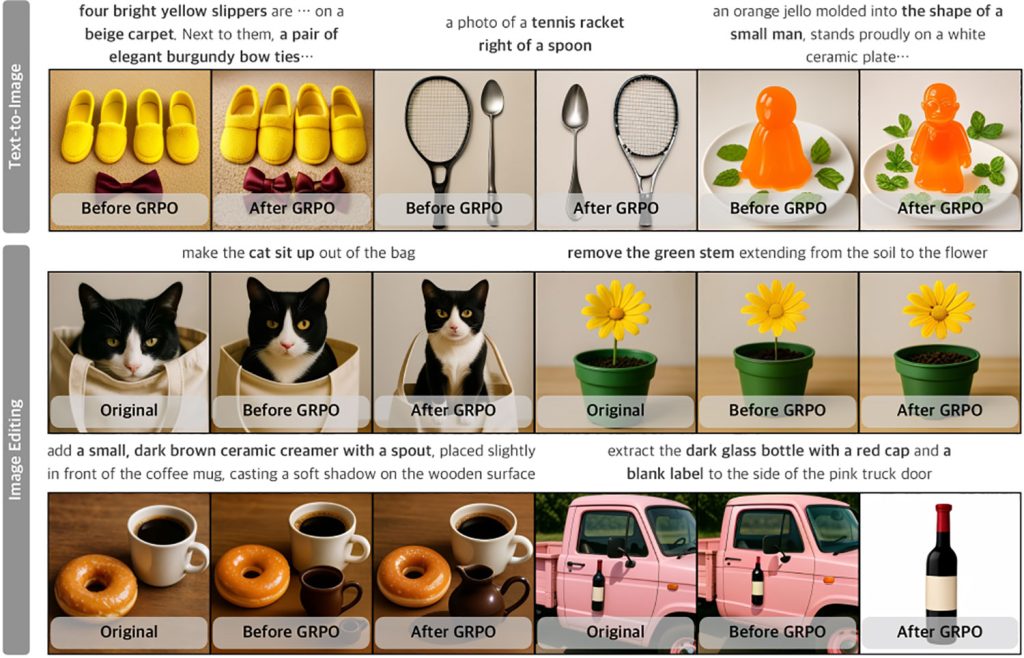
Los investigadores señalan que UniGen-1.5 tiene problemas con la generación de texto y con la coherencia de la identidad en determinadas circunstancias:
Los casos de falla de UniGen-1.5 para tareas de generación de texto a imagen y edición de imágenes se ilustran en la Figura A. En la primera fila, presentamos casos en los que UniGen-1.5 no logra representar con precisión los caracteres de texto porque el detokenizador discreto y liviano tiene dificultades para controlar los detalles estructurales finos necesarios para generar texto. En la segunda fila, mostramos dos ejemplos de cambios de identidad visibles resaltados por el círculo, por ejemplo, los cambios en la textura y forma del pelaje facial del gato y las diferencias en el color de las plumas de las aves. UniGen-1.5 necesita más mejoras para abordar estas limitaciones.

Puedes encontrar el estudio completo aquí.
Ofertas en accesorios en Amazon
![]()
![]()
FTC: utilizamos enlaces de afiliados automáticos que generan ingresos. más.




")






{kind=link}